

Prompt to Heap Overflow: Pwno's Debut CVE
Pwno's discovery of a heap overflow in Llama.cpp's Tokenizer
 Ruikai Peng
Ruikai PengToday we’re excited to showcase the first live finding discovered by Pwno, our autonomous low-level security research agent: CVE-2025-52566 - a subtle integer overflow bug in llama.cpp’s tokenizer leading to heap-overflow, quietly hiding in plain sight for over a year.
This is finding genuinely thrills us, it's the first time we seen AI find something that deep level under ML setting - Tokenizer, one of the most fundamental building blocks of language models, where in this finding, attackers can overflow the inferencing engine via a manipulated prompt. We seen similar vulnerability in other crucial ML components (e.g. GGUF Parser), but for tokenizer, it's the first time.
We'll like to commend the llama.cpp maintainers for their outstanding security response. Following responsible disclosure, the team validated the finding and merged the fix within 24 hours - Their standards to security is exemplary
And here, is our quick storytelling, and rundown of Pwno's discovery of this heap-overflow.
A Quiet Bug on a Friday night
On a quiet Friday, Pwno wrote a report about something strange it found inside llama.cpp's tokenizer implementation (specifically llama_vocab::tokenize, under src/llama-vocab.cpp:3036)
if (n_tokens_max < (int) res.size()) {It wasn't flashy just a single line. A cast, But that one cast turned out to be enough.
Tokenization Philosophy
Before diving into the vulnerability, we need to understand a bit of llama.cpp's tokenization philosophy.
Fun fact: As we dug into the tokenization internals with Pwno guiding the way, we stumbled upon an area in the tokenizer that could be optimized , so we went ahead and submitted a separate PR upstream to fix it. Security research has its perks!
llama_vocab::tokenize() acts as an interface adapter that calls the underlying tokenizer (llama_vocab::impl::tokenize), which handles the lower-level tokenization process where the inner vocab magic happens (e.g. LLAMA_VOCAB_TYPE_*, determined by tokenizer.ggml.model). We'll see later why this design choice becomes relevant when we hit another interesting bug.
int32_t llama_tokenize(
const struct llama_vocab * vocab,
// ....
return vocab->tokenize(text, text_len, tokens, n_tokens_max, add_special, parse_special);
}llama_tokenize is a thin wrapper around vocab->tokenize (the llama_vocab::tokenize interface), and it's the common tokenizer API you'll see throughout llama.cpp's implementation - directly used in run/run.cpp (./bin/llama-run's implementation) and in common.cpp (then used everywhere: server.cpp (./bin/llama-server), tts.cpp, tokenize.cpp...).
If you look closely at the callers of llama_tokenize(), you'll see they follow a common two-phase allocation pattern:
- Probe phase: Initialize a buffer for
llama_token * tokenswith a small allocation - Size discovery: Call
llama_tokenize -> llama_vocab::impl::tokenizefor the first time to probe thetokenslength, wheren_tokens_maxis set to zero or a small size to guarantee no actual copying happens - Resize:
resize()the result vector with the negative length returned fromllama_tokenize - Execute: Call
llama_tokenizefor the second time, wherellama_vocab::impl::tokenizeis guaranteed to save results underllama_token * tokens
This explains why a negative return is used for llama_tokenize - the tokenizer dynamically determines the output size of the token array. While this costs an extra call to llama_vocab::impl::tokenize, it guarantees efficient memory usage, but this design is also what makes our heap overflow possible.
Integers:
Here's the vulnerable code in llama_vocab::tokenize() at src/llama-vocab.cpp:3062:
int32_t llama_vocab::tokenize(
const char * text,
int32_t text_len,
llama_token * tokens,
int32_t n_tokens_max,
bool add_special,
bool parse_special) const {
auto res = tokenize(std::string(text, text_len), add_special, parse_special);
if (n_tokens_max < (int) res.size()) { // ← THE VULNERABILITY
return -((int) res.size());
}
for (size_t i = 0; i < res.size(); i++) {
tokens[i] = res[i];
}
return res.size();
}The line if (n_tokens_max < (int) res.size()) converts the tokenize(...).size() (std::vector.size(), which is size_t) into (int) for comparison with n_tokens_max.
The casting seems intuitive - since n_tokens_max is int32_t (signed), the result size() gets cast to a signed int to avoid compiler warnings about signed/unsigned comparison and ensure both operands have the same signedness.
But here's where things get spicy. In an edge case where res.size() exceeds INT_MAX (2,147,483,647), the casting converts the originally huge size_t res.size() into an extremely large negative integer due to signed integer overflow. This negative value will always be less than n_tokens_max - which in normal cases is always a small integer (remember, the dynamic size probing design starts n_tokens_max at zero).
For the follow-up memory operation, the originally int-casted res.size() gets restored back to its original size_t type - from the negative integer used in size comparison back to the huge positive integer. In a case where res.size() = 2,147,483,647+1, this allows (actual_tokens-2,147,483,648)*sizeof(llama_token) bytes of out-of-bounds writing.
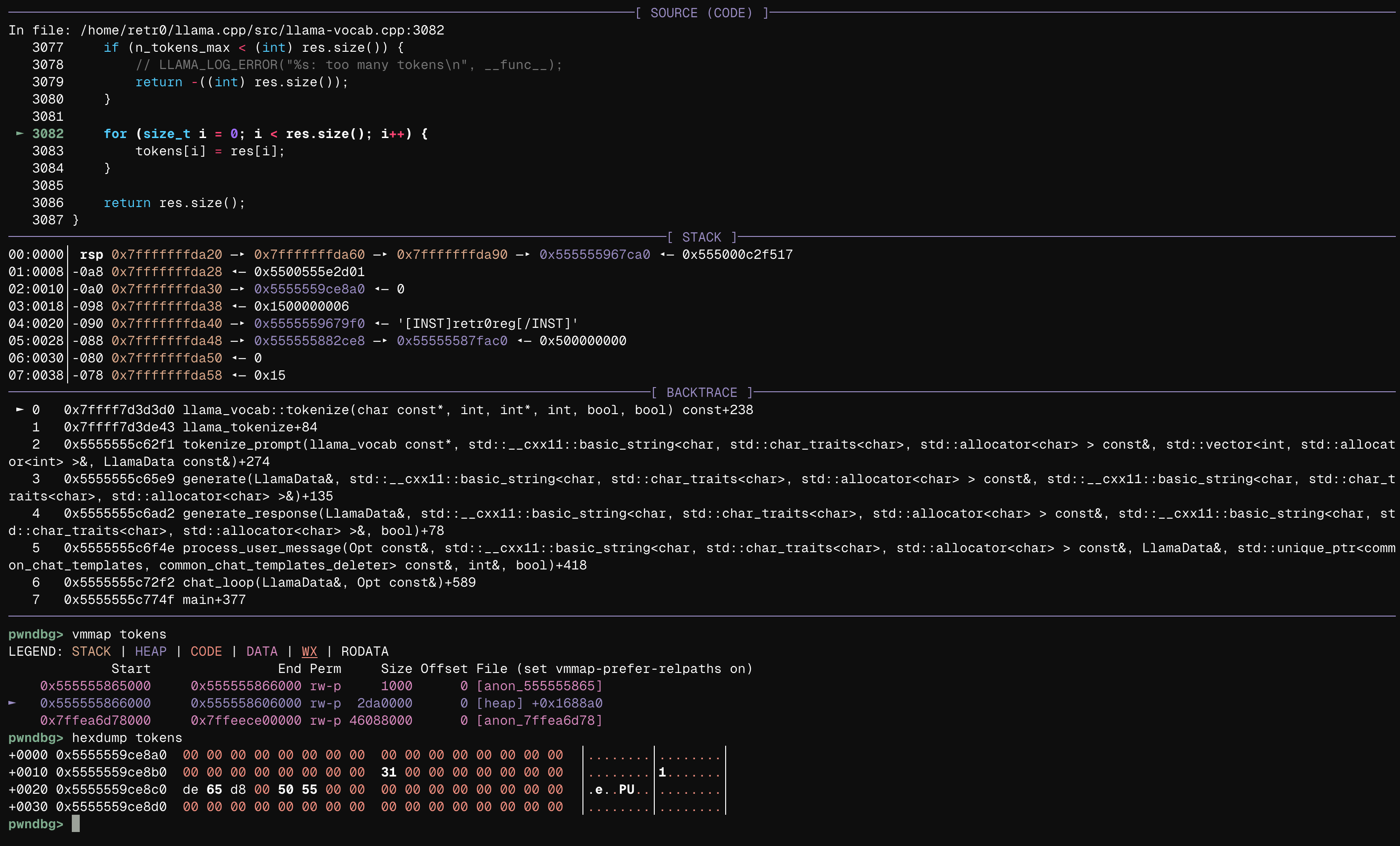 From
From gdb, we can see that the final copied destination token is located on the heap, confirming this is a heap overflow. And trust us, heap overflows are both interesting and dangerous.
std::vector larger than max size()?
However, creating such a huge input is usually problematic since the C++ standard library has protections against creating oversized elements. This was a major obstacle when creating a proof-of-concept for this heap overflow, since directly inputting such a lengthy prompt triggers:
what(): cannot create std::vector larger than max size()Tracing this error, we found it's triggered by std::vector<char> buf(alloc_size) in the legacy chat template processing path:
// (common/chat.cpp:1831) common_chat_templates_apply_legacy
static common_chat_params common_chat_templates_apply_legacy(
const struct common_chat_templates * tmpls,
const struct common_chat_templates_inputs & inputs)
{
// ....
for (size_t i = 0; i < contents.size(); ++i) {
const auto & msg = inputs.messages[i];
const auto & content = contents[i];
chat.push_back({msg.role.c_str(), content.c_str()});
alloc_size += (msg.role.size() + content.size()) * 1.25;
}
std::vector<char> buf(alloc_size); // Boom!The size is determined by alloc_size += (msg.role.size() + content.size()) * 1.25, and that * 1.25 multiplier makes our originally huge content.size() even bigger, triggering the size limit.
But looking at common_chat_templates_apply, we noticed something interesting:
common_chat_params common_chat_templates_apply(
const struct common_chat_templates * tmpls,
const struct common_chat_templates_inputs & inputs)
{
GGML_ASSERT(tmpls != nullptr);
return inputs.use_jinja
? common_chat_templates_apply_jinja(tmpls, inputs) // ← This path!
: common_chat_templates_apply_legacy(tmpls, inputs);
}The Jinja path (llama.cpp's chat template interpreter) never allocates a manual byte-buffer the way the legacy path does. Instead:
- It builds a
templates_paramsstructure (all members are default-constructed; nothing is pre-sized) - It dispatches to helpers like
common_chat_params_init_llama_3_x - The rendered prompt is obtained via
minja::chat_template::apply, which directly returns anstd::string
Memory management is handled automatically by std::string with no explicit size estimation required. This means using common_chat_templates_apply_jinja (via the --jinja flag) lets us bypass the size error entirely!
The Collateral Gift
During our PoC creation, something sketchy caught our attention in the ASAN logs:
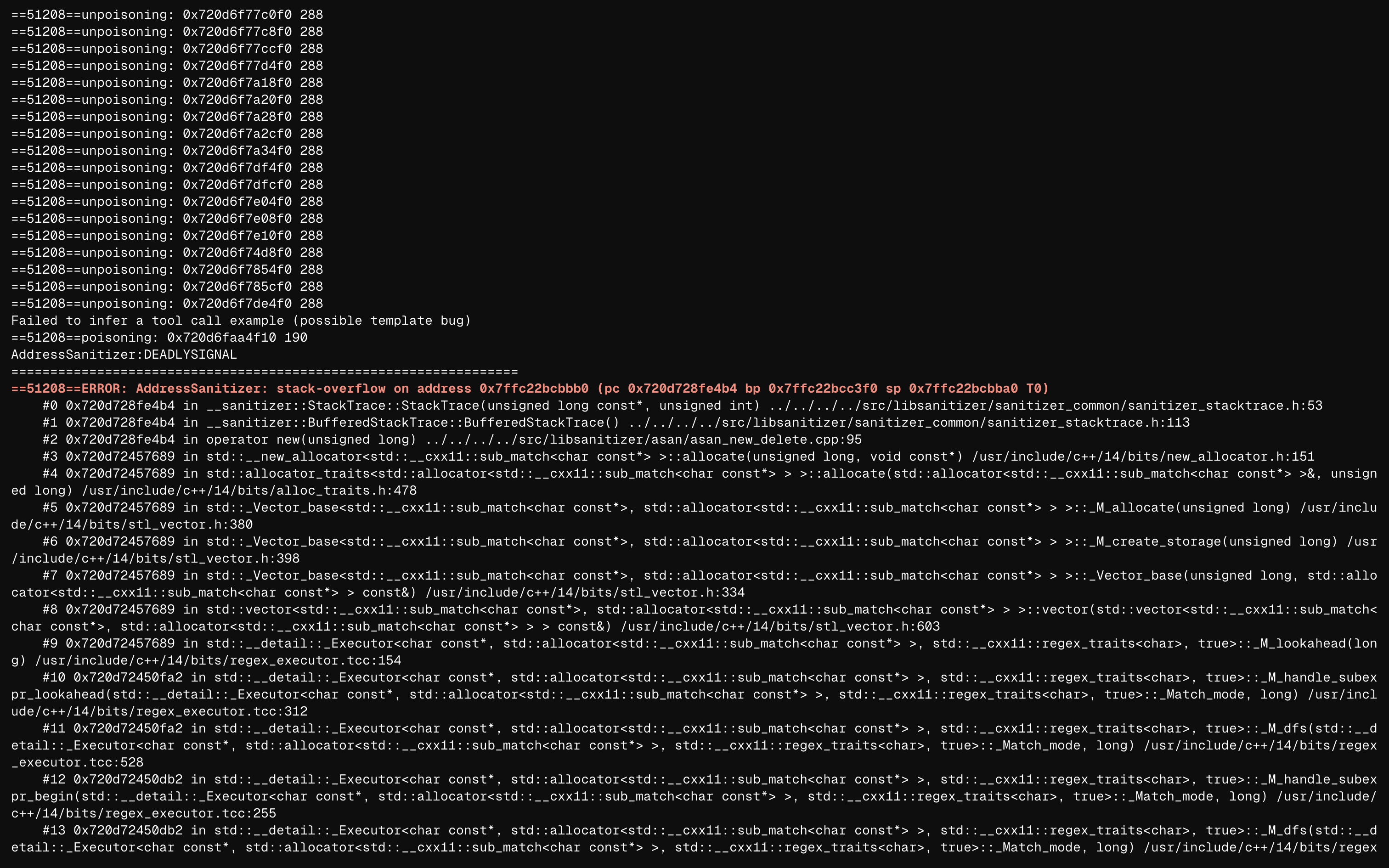
A stack overflow was triggered via the STL allocator (bits/alloc_traits.h). At first, we thought this was our heap overflow (we didn't realize it was actually a heap overflow back then), but examining the detailed ASAN logs revealed this was via regex processing (bits/regex_executor.tcc).
Further investigation showed this stack overflow was caused by infinite recursion in unicode_regex_split, pushing the stack frame to its upper limit:
void tokenize(const std::string & text, std::vector<llama_token> & output) {
int final_prev_index = -1;
const auto word_collection = unicode_regex_split(text, tokenizer.regex_exprs); // Boom!You can view this from two perspectives: On one hand, we got a collateral ReDoS vulnerability out of the blue; on the other hand, this stack overflow was preventing us from reaching our original heap overflow target.
*But there's always a way around these things, This regex splitting (unicode_regex_split) only happens in LLAMA_VOCAB_TYPE_BPE, the most common vocab type used by GPT-2 (Byte-Pair Encoding). By switching to Unigram (T5) architectures in the GGUF metadata (LLAMA_VOCAB_TYPE_UGM), we can take a different case in the llama_vocab::impl::tokenize() switch and avoid the problematic regex processing entirely.
Impacts
While this discovery represents a Pwno's theoretical breakthrough, we want to be transparent about its real-world implications, and directly pointing out that this vulnerability requires specified conditions to be exploitable - including carefully crafted input and specific settings (
Jinjatemplating enabled). Withllama.cppprompt response on security, most real-life inferencing cases should not be effected:)We don't want to sensationalize our findings or create unnecessary alarm.
Remote Code Execution: The heap is very playful. We can overwrite following chunks (freed or in-use, both dangerous!) and their member pointers:
- Overwrite in-use structure members: Change initialized chunk interfaces to bad pointers, hijack execution flow, structure-oriented programming attacks
- (You can read llama's paradox for my past experience turning a heap overflow in
llama.cppinto RCE.)
- (You can read llama's paradox for my past experience turning a heap overflow in
- Overwrite chunk states/freed chunk pointers: Classic house-of attacks Denial of Service: Crashes the inferencing server (straightforward but effective)
Timeline:
- Discovery: June 19, 2025
- First Response: June 19, 2025
- Validation: June 19, 2025
- Patch PR: June 20, 2025
- Merged: June 20, 2025
- Second PR: June 22, 2025 (tokenization optimization)
- Merged: June 23, 2025
- Disclosure: June 27, 2025 (Coordinated disclosure to
llama.cppteam) - CVE Assignment: CVE-2025-52566
How did Pwno find it?
For Pwno's multi-architecture design, we design and implemented a multi-agent system specifically for autonomous low-level security research.
We been focusing on security automation specifically for low-level security for the past two years, we developed AutoGDB, BinaryChat, at the early time, we're speaking at Black Hat USA this summer about Tree-of-AST, something we worked since September last year, we also had learnt alot from promising low-level security research automation along the way (e.g. Google Project Zero, DarkNavy, Sean Heelan's post is great).
One fun design we implemented for this research, is the professor system for Pwno to access a agent-based RAG for informations (about the framework, exploitation methodologies, past discoveries)
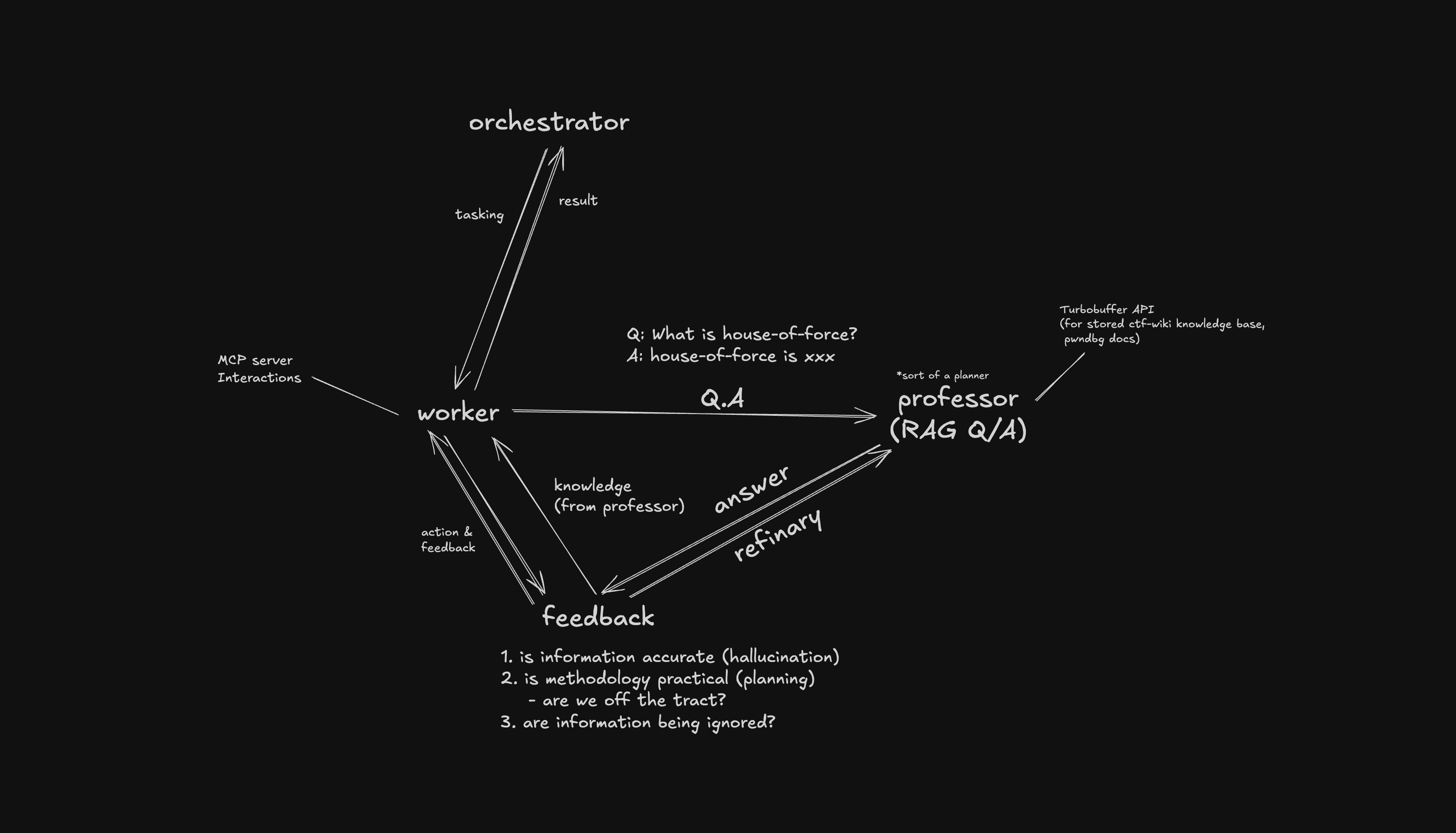
One fun thing we did, is we input previous advisory report and security-related PRs to professor's database. Pwno was intrigued by one past overflow in advisory GHSA-8wwf-w4qm-gpqr. (Where I personally worked on for the past with Guy Goldenberg at wiz security). The two reports resembles in the tokenization components, both dependent to llama.cpp's Tokenization Philosophy of size probing behavior (a reason why we put emphasis on that previous).
However, with the discovery of the sink, Pwno was able to dynamically explore and debug the compiled llama.cpp service (specifically llama-run) for a further lower-level of research and exploration of the calling process, we seen Pwno made unexpected and surprising findings, for example as we introduced bypassing std::vector larger than max size() via Jinja template memory allocation designs and bypassing redos by understanding llama.cpp vocab internals switch cases in order to reach for a furthermore severe heap-overflow.
The reason why we put so much faiths on Transformers on low-level security is because they're natural processor of information, the only part where they're naturally better than us as human is their granularity in context awareness - something engraved in their attention heads designs, contextualizing every single piece token in the information - this allows them to see something that we can't (we can only pay attention to a certain amount of information at a time, but their attention (the ability to pay attention to more, and distracted to more) is easily scalable by computation powers).
And what made low-level exploitation harder in general comparing to higher level of security research (e.g. web), is the high level of abstractions and the amount of informations you take in, and it's harsher requirement to extrapolate (reason based informations you have(patterns you observer, learnt in the past), and apply it with the newer things) based on the former. At the end of the day, the ability to invent or research is based on a matter of volume and granularity of the process of information; the more complex the task is, the more the importance of volume and granularity manifests.