

Pwno in Reverse: One shotting 'Volcano' with SMT Solver
Pwno MCP reverse-engineering a CTF challenge with SMT Solver
 RC
RCPwno on CTF Challenges
CTF challenges are widely regarded as one of the best ways to learn real-world tools and techniques used in cybersecurity. They provide a hands-on experience that allows participants to apply theoretical knowledge in practical scenarios. For experienced researchers, they also serve as a means to learn new techniques and evaluate their skills in different categories.
While such is the case for human researchers, we wanted to put our MCP server's tool ability to aid in such challenges. To our surprise, in a lot of the challenges we tried to solve using the MCP server along with different agents (once a custom agent and once with the opencode agent) it managed to one-shot challenges without any human intervention and directly found the flags.
This shows the effectiveness and the precision of the Pwno MCP. We describe effectiveness as the ability of the AI agent to solve a task only with the available tools from the Pwno MCP server. This effectiveness, in the cases we have seen, seems to be very high for our MCP server. Since the server comes with a small set of well-written tools and they have shown that they are enough for solving a moderate-level task. You can find the tools available here
We define precision as the amount of clarity the agent has on the tool use. It concerns questions like:
- Does the agent invoke multiple tool calls to do something that it could achieve by using fewer tool calls?
- Does the agent call tools that are unrelated to the task at hand?
- Does the description of the tool accurately define the tool and how it must be called?
However, we would like to clarify that we do not intend to use these as benchmarks in the current context. They are just a way for us to evaluate the usefulness of our MCP server.
Volcano
The first challenge we attempted to solve with the MCP server was volcano. It is a challenge from Amateurs CTF in the Reverse Engineering category. Let us start by doing a proper analysis of the challenge.
Analysis
This is the decompilation of the main function:
int main(int a1, char **a2, char **a3)
{
...
printf("Give me a bear: ");
v7 = 0;
scanf("%llu", &v7);
if (sub_0_12BB(v7) != 1)
{
puts("That doesn't look like a bear!");
return 1;
}
else
{
printf("Give me a volcano: ");
v8 = 0;
scanf("%llu", &v8);
if (sub_0_13D9(v8) != 1)
{
puts("That doesn't look like a volcano!");
return 1;
}
else
{
printf("Prove to me they are the same: ");
v9 = 0;
v10 = 4919;
scanf("%llu", &v9);
if ( (v9 & 1) != 0 && v9 != 1 )
{
v4 = sub_0_1209(v8);
if ( v4 == sub_0_1209(v7)
&& (v5 = sub_0_124D(v8), v5 == sub_0_124D(v7))
&& (v6 = sub_0_1430(v10, v8, v9), v6 == sub_0_1430(v10, v7, v9)) )
{
puts("That looks right to me!");
stream = fopen("flag.txt", "r");
fgets(s, 128, stream);
puts(s);
return 0;
}
...Put simply, the program takes three inputs, verifies each one of them and if they satisfy some requirements, it prints the flag. Now, the process of solving this CTF challenge is all about just figuring out what these functions are checking.
A simple analysis of these functions reveals that they are using a bunch of mathematical constraint checks on the input, for example this is the decompilation of the function sub_0_012BB:
int sub_0_012BB(unsigned long long a1)
{
if ((a1 & 1) != 0)
return 0LL;
if (a1 % 3 != 2)
return 0LL;
if (a1 % 5 != 1)
return 0LL;
if (a1 % 7 == 3)
return a1 % 0x6D == 55;
return 0LL;
}Similarly, another function sub_0_13D9 also contains such constraints:
int sub_0_13D9(unsigned long long a1)
{
unsigned long long a1
unsigned long long v2;
v2 = 0LL;
while (a1)
{
v2 += a1 & 1;
a1 >>= 1;
}
return v2 > 0x10 && v2 <= 0x1A;
}Such challenges are classic examples of problems that require using Satisfiability Modulo Theories (SMT) Solvers. These SMT solvers help us model constraints programmatically and solve them using mathematical methods, the details of which are not terribly important. Solving these problems usually requires reading all the constraints and then modeling them using an SMT solver like z3 or sympy. Depending on the complexity of the challenge this could be a very tiring process. Attempts have been made to automate this process before and using AI agents to do it seems to be the natural progression.
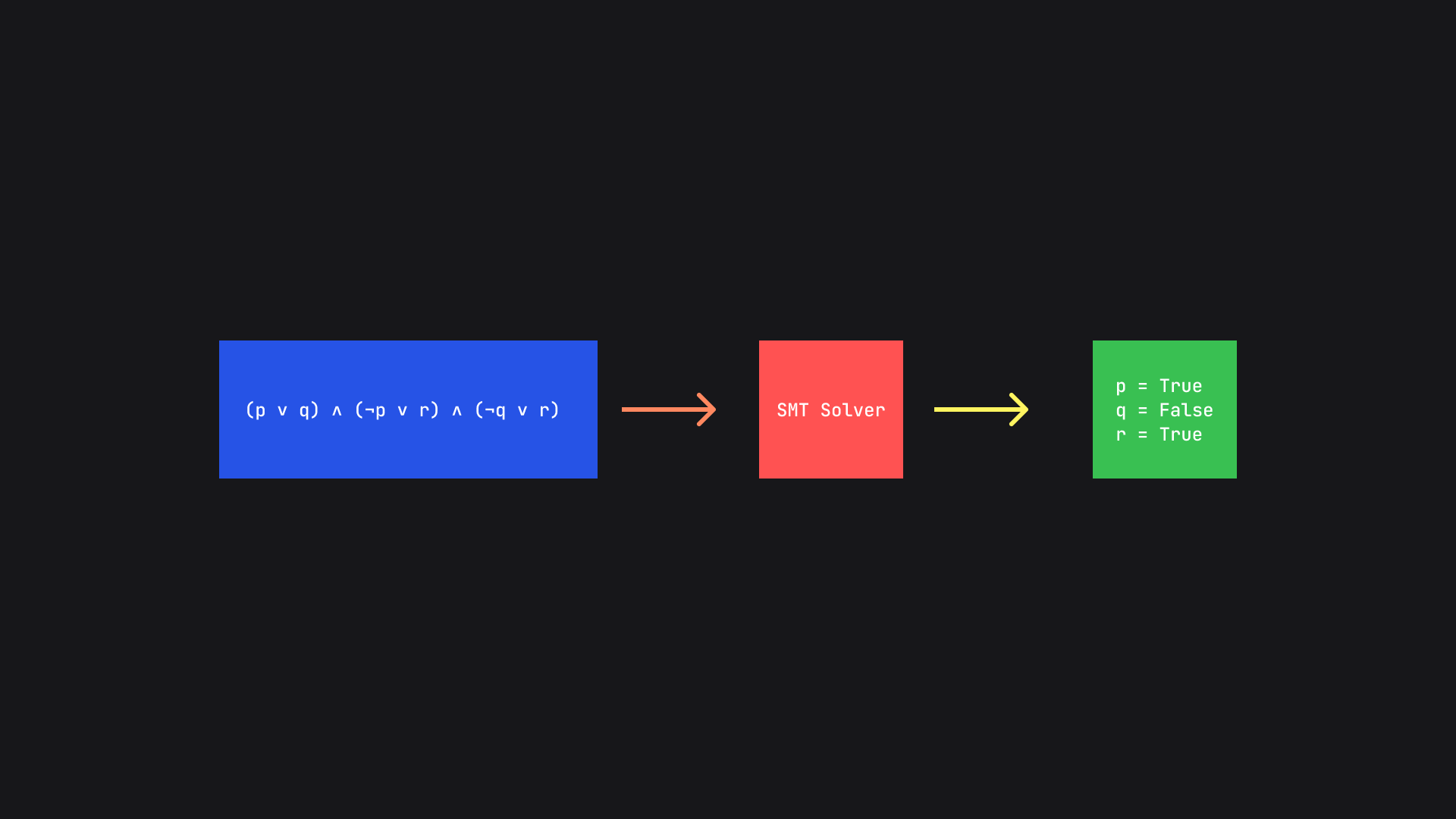
Agents in action
What prompt the agent is given to initiate the process, the system prompt of the underlying LLM, the context available to it, etc. greatly determine how it plans to solve the given challenge and can be the make-or-break factor of the whole process, no matter how good the MCP server is.
We verified this by connecting the Pwno MCP server with the opencode command line coding agent. The benefits of using opencode are the fact that we do not have to write an agent from scratch and since the agent is made for software engineering tasks it is able to understand the whole context and solve the challenge using only tool descriptions available from the hooked MCP server. Here's one single prompt that let the agent solve the whole challenge in one shot:
The binary volcano is from a CTF challenge, initial analysis reveals this challenge requires an SMT solver to solve. Start by finding the main function, analyzing and collecting constraints from it and putting them in a script to solve it with z3. Use the Pwno MCP server. For some context, the part for finding the main function is often required because a lot of CTF challenges are often stripped and we want that part to be explicit in the planning process of the LLM.
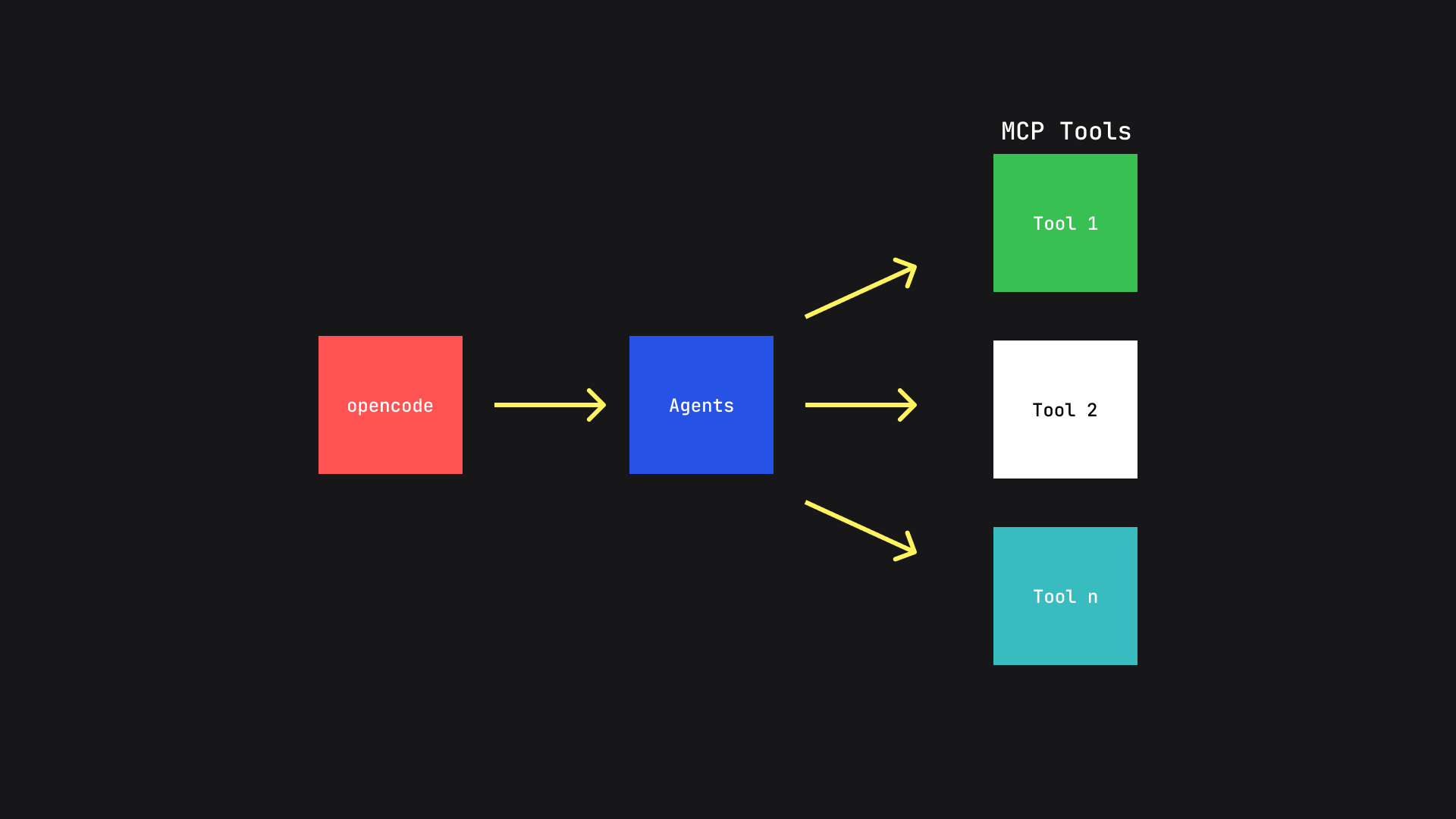
Since LLMs do not produce predictable and consistent outputs, they plan different things on every run. This makes it hard for us to document what the agents do to solve the challenge.
For this reason, we wrote two custom agents: The first one was told to do an initial analysis of the binary, study its behavior by debugging and doing common checks to create a report which would be read by the second agent, whose chief task is to create a plan to do final analysis of the binary and get the flag.
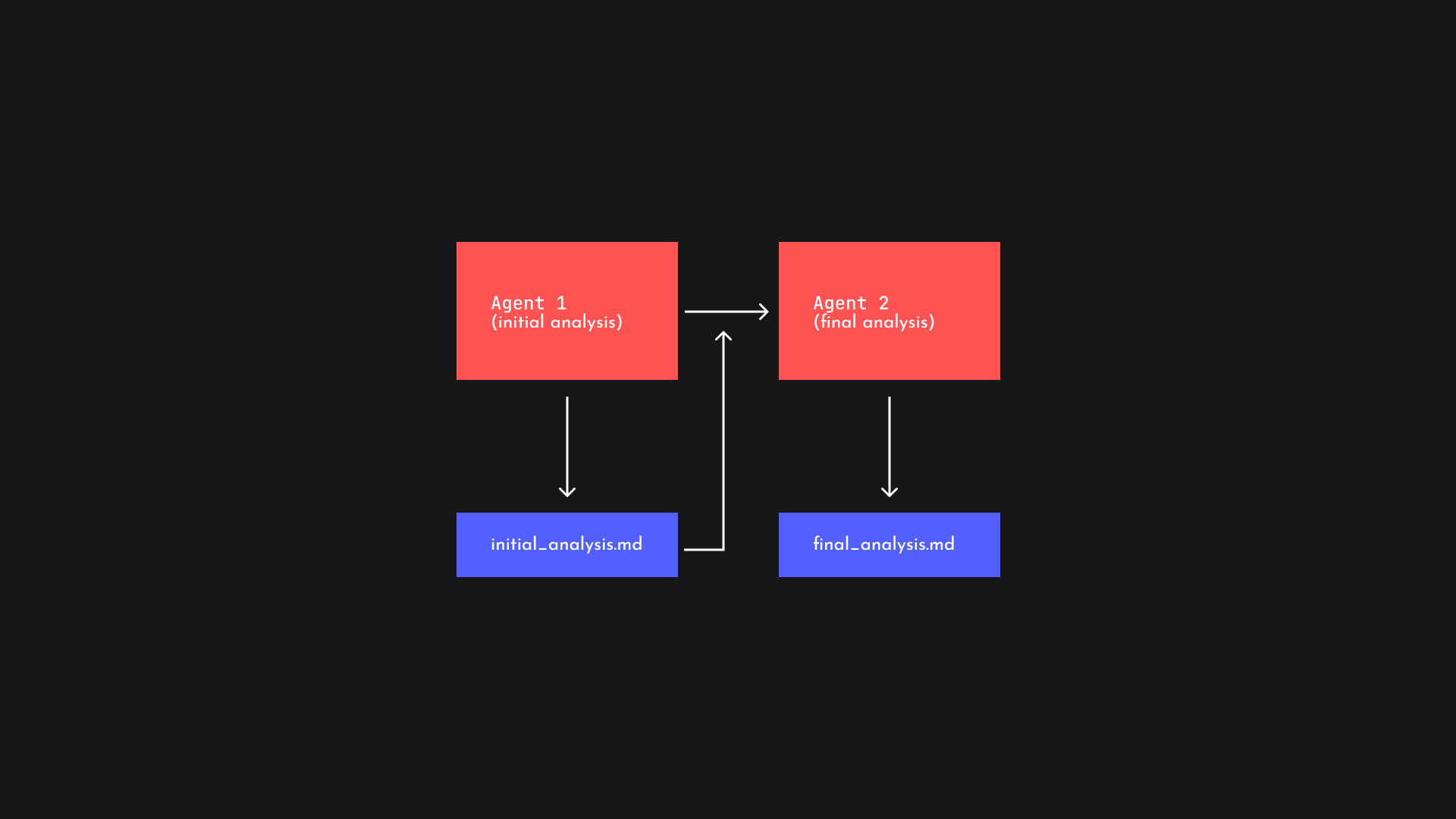
This would help us reveal the tracing and the thought process of the LLM to some level. Below are some important excerpts from the initial analysis which reveal how the agent effectively communicates important details to the second agent to continue its analysis:
## Function inventory and summaries (key ones)
Addresses are binary offsets (PIE). For each, a short summary is provided.
...
## Tools used
- GDB/pwndbg via functions.set_file, functions.execute (disassembly, entrypoint, call graph)
- strings(1) via functions.run_command (prompt and filename extraction)
- Python (CRT solver, search) via functions.execute_python_code
...
## Where is main?
- Entrypoint (_start) at 0x1120. At 0x1141 the code loads rdi = 0x14a7 and immediately calls __libc_start_main via the PLT. This rdi is the main() pointer.
- Conclusion: main is at 0x14a7 (file offset; add the PIE base at runtime).
...
- 0x1209 — dec_digit_count(uint64_t n) -> uint64_t
- Counts the number of decimal digits of n by iteratively dividing by 10 using the 0xCCCC... magic multiply.
- Returns number of decimal digits.
- 0x124d — dec_digit_sum(uint64_t n) -> uint64_t
- Computes sum of decimal digits of n; loop: sum += n % 10; n /= 10 (again using the 0xCCCC... magic for /10).
- Returns sum of digits.
- 0x12bb — is_bear(uint64_t n) -> bool
- Rejects if n is odd; requires n even.
- Requires the following congruences (via multiplicative inverses/magic divisors):
- n % 3 == 2
- n % 5 == 1
- n % 7 == 3
- n % 109 == 55
- Returns 1 if all hold, otherwise 0.
- 0x13d9 — popcount_range_ok(uint64_t n) -> bool
- Computes popcount(n) by shifting and accumulating bits.
- Returns 1 iff 17 <= popcount(n) <= 26; otherwise 0.
- 0x1430 — powmod(uint64_t base, uint64_t exp, uint64_t mod) -> uint64_t
- Fast modular exponentiation (square-and-multiply):
- Acc = 1; base %= mod; while exp>0: if (exp&1) Acc = (Acc*base)%mod; exp >>=1; base = (base*base)%mod; return Acc.
...This information, paired with the following excerpt reveals the extreme usefulness of this initial analysis report:
## User-controlled inputs and validations
Inputs (via scanf "%llu"):
1) bear (uint64)
- Must satisfy even AND the congruences: n%3==2, n%5==1, n%7==3, n%109==55.
2) volcano (uint64)
- Must satisfy 17 <= popcount(volcano) <= 26.
3) flag_index (uint64)
- Must be odd and NOT equal to 1.
- Additionally, must make powmod(4919, volcano, flag_index) equal powmod(4919, bear, flag_index).
Further cross-input constraints:
- dec_digit_count(volcano) == dec_digit_count(bear)
- dec_digit_sum(volcano) == dec_digit_sum(bear)
## How to craft inputs that pass (and reveal the flag on the challenge server)
- Bear: Solve the system using CRT.
- n ≡ 0 (mod 2), n ≡ 2 (mod 3), n ≡ 1 (mod 5), n ≡ 3 (mod 7), n ≡ 55 (mod 109)
- The general solution is n ≡ 18476 (mod 22890); i.e., bear = 18476 + 22890·k.
- Pick k so that bear has the desired number of decimal digits and plays nicely with volcano (see below).
- Volcano: choose any integer with 17..26 set bits. For convenience, use a 6+ digit number to make popcount≥17 feasible. You must also match both the decimal digit COUNT and the decimal digit SUM of the chosen bear.
- flag_index: choose any odd number > 1 that makes powmod(4919, volcano, flag_index) == powmod(4919, bear, flag_index).
- A robust choice is a prime P not dividing 4919 such that (P-1) | (volcano - bear). Then by Fermat's little theorem, 4919^(volcano) ≡ 4919^(bear) (mod P).Any experienced researcher in this domain can look at this report and manage to solve this problem from here within a short time period. The details are impressive and well put. Similarly, it helps the second agent directly get to work by creating a plan and executing it sequentially (ideally). With such perfect information from the first agent, the second instantly finds the flag out in 4 steps, which are as above:
Step-by-step execution
Step 1: Constraints recap from initial_analysis.md
- bear (A): even; and A % 3 == 2; A % 5 == 1; A % 7 == 3; A % 109 == 55
- volcano (B): popcount(B) in [17, 26]
- Cross-checks: digit_count10(A) == digit_count10(B); digit_sum10(A) == digit_sum10(B)
- modulus (M): odd and > 1; and powmod(4919, A, M) == powmod(4919, B, M)
- Success prints: "That looks right to me!" then contents of flag.txt
Step 2: Protections (checksec)
- Command: checksec on /home/rc/agentic-tests/volcano
- Result: Full RELRO, Canary, NX, PIE, SHSTK, IBT all enabled. Confirms this is a math/logic validation challenge.
Step 3: Validate failure modes dynamically
- Invalid bear (A=2):
$ printf '2\n' | ./volcano
Output: "That doesn't look like a bear!"
- Valid bear but invalid volcano (A=132926, B=1):
$ printf '132926\n1\n' | ./volcano
Output: "That doesn't look like a volcano!"
- Valid bear/volcano but invalid modulus (M=1):
$ printf '132926\n507902\n1\n' | ./volcano
Output: "That's not a valid proof!"
Step 4: Provide a valid triple and capture the flag
- Working inputs (from initial report and validated here):
- bear = 132926
- even; %3=2; %5=1; %7=3; %109=55
- volcano = 507902
- popcount=17; 6 digits; digit sum matches bear
- modulus = 5 (odd > 1 and (5-1)| (volcano - bear))
- Command:
$ printf '132926\n507902\n5\n' | ./volcano
- Program output:
Give me a bear: Give me a volcano: Prove to me they are the same: That looks right to me!
DUMMY_FLAG{example}And there we go! The challenge is solved! There are a few insights to gain from here, let us talk about them next.
Insights
Let us now transparently discuss the details of this agentic run. There are only a few areas of concern other than the available tools which we have already discussed.
Large Language Model
The choice of model certainly is the most important choice we make when we are creating agentic workflows. Reasoning models greatly outperform non-reasoning models on tasks where planning is required because of their multi-step feedback-to-self loop; this turns out to be extremely effective for our use case.
In our testing, we have verified this fact about reasoning models. The ability to one-shot challenges, at this point, is mostly specific to reasoning models. Non-reasoning models usually either totally start hallucinating details or take multiple attempts with different strategies one by one to try to solve the challenge, which we do not consider as "one-shotting."
One interesting insight we get from this is the fact that while reasoning models may seem to take more tokens to solve a challenge than non-reasoning models, it is usually not the case. Due to the precision we get from the reasoning models' effective and precise planning, they often use fewer tokens to complete the tasks at hand. Non-reasoning models have to spend a high number of tokens to correct their wrong assumptions and hallucinations, which leads to a very high expenditure of tokens. Such reasons make non-reasoning models not ideal for us.
The next question at our hand is which model to even use. In our testing we have found that all the major LLMs perform almost equally. Depending upon the cost requirement, one can optimize for their use case. While Anthropic's Claude 4.1 family at this point seems to be the most promising when it comes to our agentic workflows, the cost of running them is extremely high. Instead, the gpt-5 models from OpenAI seem to perform equally well on these evaluations and their pricing is also reasonable. Even on the runs we discussed in this post, we were using gpt-5 with reasoning effort set to high, thus even further verifying the fact that gpt-5 is a good choice for agentic workflows.
Prompts
The specific way our agent does its work and plans its execution is highly dependent on the prompts we are using for each agent, as well as the system prompt for the LLM we are going to use. Since we are using two agents, we will now describe each prompt and specific reasons if there are any for using them. For the first initial analysis agent, the prompt is as above:
You are a binary researcher with years of experience in reverse engineering. You are deployed inside an environment where you have to analyze a binary(ies) depending upon the user request.
Right now, your chief task is to create an initial analysis report of the binary using the tools that you have. Your detail should be thorough and it should contain a few key things.
- Address of the main function
- In some binaries, the main function is simply not there because of stripping, static linking or any other reason. Your job is to use dynamic analysis with the available debugger to find the main function's address. In some cases it may not be clear, so you must specify that.
- Interesting functions list with their addresses
- List all the functions inside the binary and then disassemble every function one by one to gain an understanding of which function is doing what. Then put that into the report.
- Interesting paths
- Analyze the binary's code for interesting functions like functions which are commonly associated with vulnerabilities, common patterns which lead to issues, etc. Put them in a separate block
- Your main focus should be on the areas of code we can influence through user input or any user controlled data. This will give us a way to look when doing further analysis
The rest is up to you to decide.
Use all the available tools at your arsenal properly. Always list them first and then find out which one you want to use.
Note: For decompilation, you should use the MLM decompiler and if it doesn't work after a few tries you can try RetDec.
Based on the patterns of code inside the binary try to categorize and even subcategorize them into categories like "CTF", "Vulnerability Analysis", "Binary Exploitation", "Crackme", "Patching", etc.
Subcategories are dependent on the category, so for "CTF" subcategories may be "SMT Solver", "Keygen", "Binary Exploitation", "Reverse Engineering", etc.
For "Binary Exploitation" it may be "Heap Exploitation", "Buffer Overflow", etc.
At the end of the analysis, always make sure to hint to categorize and optionally subcategorize it.
Otherwise ask for more analysis.
Never manually calculate anything. Always use tools or crypto modules or any SMT solver to model the conditions.
This report will be read by another AI agent which will do further analysis. Write the report in a way that it knows exactly what to do next. You could prompt engineer it to do specific things. Your report is also a prompt for it.
In case you find the exploit, flag or anything interesting, in the initial analysis itself, you can mention it in the report and just ask the next agent to verify it in the prompt.
Use markdown for this report.
Save this report as initial\_analysis.md in the same folder as where the challenge was savedIf you remember the way the previously mentioned report was written, it directly follows the rules specified here. This reveals to us that writing good prompts is an unskippable part of working on useful agentic workflows as some models seem to effectively follow these guidelines.
There could obviously be a better prompt for this task, this one is just what we used.
Moving ahead, the following is the prompt we used for the second agent:
You are a binary analyst, reverse engineer, exploit developer and an excellent ctf player with more than 30 years of experience. Based on the earlier report from the initial analysis agent (stored at initial\_analysis.md) you will do further dynamic analysis of the binary.
Start by making a plan based on the initial analysis. This initial analysis file is inside the challenge folder. Spend some time on it. It must be unambiguous and detailed. And then follow it step by step.
This analysis will be focused on the category/subcategory of the binary. You will look at specifics of the binary and try to find bugs, exploit vulnerabilities and even find flags if it is a ctf challenge.
After the analysis is complete save the report as dynamic\_analysis.md and detail all the findings, flags, behaviors, etc.
Use all the available tools at your arsenal properly. Always list them first and then find out which one you want to use. instructions on how to continue the analysis. Therefore, read it carefully and follow it step by step.
Sometimes, the initial analysis agent may have already found the flag or exploit. In that case, your job is to verify it and provide a detailed explanation of how it works.
In any case, if you find the flag or exploit, you must provide a detailed explanation of how it works and must create solution files, scripts, etc. to demonstrate it. and do not delete them from the folder. Save them to the same folder as where the challenge is saved.
Note: For decompilation, you should use the MLM decompiler and if it doesn't work after a few tries you can try RetDec.
Save this report as initial\_analysis.md in the same folder as where the challenge was savedThere is nothing surprising here, we are continuing to tell the agent what to do in an unambiguous way which it follows properly.
Conclusion
AI agents show a promising future of security research. One by one advancements and new optimizations in different areas of LLMs, MCP servers, etc. will improve the speed, precision and the usefulness of these workflows.
The whole process of creating AI agents from scratch is definitely a heavier task than it appears to be, especially for cases where we depend entirely on the latent space of the LLM at hand to do our tasks. In such cases, using the right LLM and the right set of tools are the major factors of whether it will be any useful to the job at hand.
We hope this blog taught you something new about agentic workflows and how we do research on our end for Pwno.